
3 a.m. An alert. You open five tabs — the infra dashboard, the APM, the network tool, the SIEM, the runbook wiki — and twenty minutes later you know that something is wrong without knowing what changed since last night. That’s the blind spot of most observability stacks: plenty of signals, few answers.
Building that stack for clients for eleven years, we ended up mapping two recurring gaps in the modern open-source stack. The first is at the bottom, in collection. The second is at the top, in comprehension. We built one open-source tool for each: SenHub Agent and Toise. Here’s the story — and why it holds together as a single thread.
Gap #1 — collection is a zoo of agents
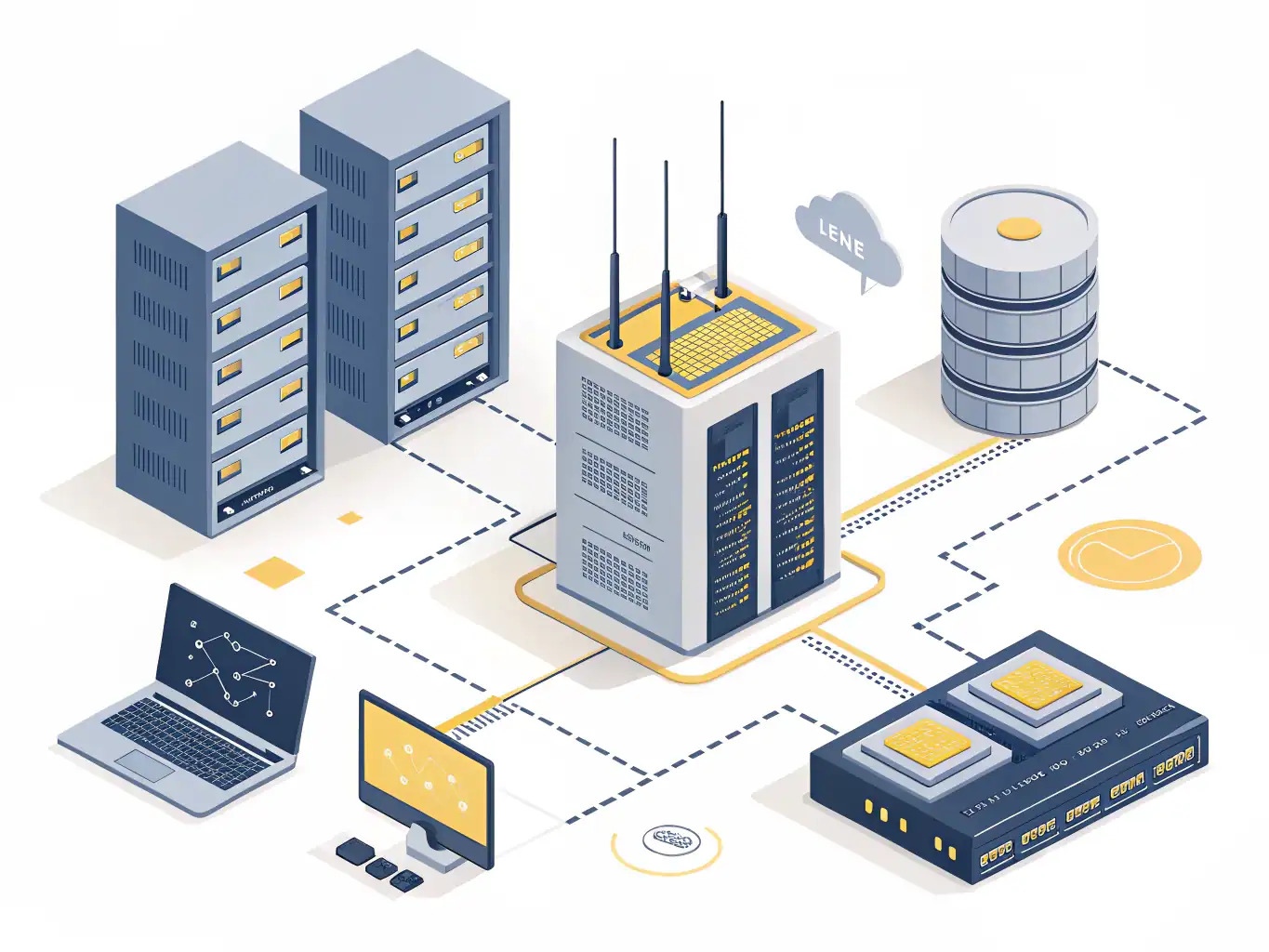
Look at any mid-market infrastructure: a Prometheus agent here, a homegrown exporter there, a PRTG sensor on the Windows servers, a Nagios plugin on the legacy boxes, a cloud collector for the rest. Each tool speaks its own dialect. Metric names diverge, units too, and the day you decide to move to OpenTelemetry you discover that “migrating” means re-instrumenting ten different chains.
SenHub Agent starts from the opposite premise: collect once, export everywhere. A single Go binary (~9 MB, zero dependencies) carries probes — operating systems, databases, hyperconverged appliances, backup software, network gear — and emits everything through one OpenTelemetry pipeline. The same data comes out as OTLP, as Prometheus, and natively as PRTG and Nagios, with one vocabulary end to end.
- One agent, not ten. You add a probe in YAML; you don’t glue together third-party exporters.
- One vocabulary across every output: names, units and attributes match across PRTG, Nagios, Prometheus and OTLP.
- No big bang. Keep PRTG or Nagios today, and the same collection feeds your OTel stack the day you switch. Migration becomes a change of output, not of sensors.
- Open-core, Apache 2.0: free OS probes, vendor probes (Citrix, NetScaler, Veeam, Redfish…) in Pro.
In practice: agent.senhub.io. It’s also the technical engine behind our Monitoring as a Service.
Gap #2 — you have metrics, not understanding
Say collection is clean. You now have terabytes of time series. But a metric answers “is it down?“, rarely “why?“, and almost never “what changed?“. Yet 80% of incidents start with a change: a deployment, a network route, a dependency that moved. That information — inventory, topology, how they evolve over time — isn’t in your metrics.
Toise is the missing brick: a living, time-aware map of your infrastructure. Which objects exist (hosts, processes, interfaces, addresses, routes, services), how they connect, and — above all — how all of it changes. The log is event-sourced and bi-temporal: not just “what is the state”, but “what changed, when, and how is it different from yesterday”.
And because the real question during an incident is never a well-formed SQL query, Toise ships a native MCP server: your AI assistant queries the graph in plain language, on your behalf. “Which switches did host db-07 depend on last Tuesday — and what changed since?” becomes a question you ask, not a twenty-minute investigation. Humans keep a GraphQL API and a built-in debug UI.
Toise is in early development, in the open: the architecture, data model, OTLP ingestion and MCP server are under active design. It sits at the core of our AI-observability work (Ops Center project). Follow it at toise.dev.
The thread: OpenTelemetry end to end
The two tools aren’t two products side by side: they interlock. SenHub Agent emits OpenTelemetry entity events; Toise ingests them to build its graph. OTLP is the backbone — no proprietary protocol, no homegrown collector to maintain, no translation layer. You can in fact feed Toise from any OTel producer (a standard Collector, your own instrumentation), not just from SenHub Agent.
That choice has three direct consequences for you:
- No lock-in. Open standards, Apache 2.0 licence. Your observability stays reversible and integrable.
- Sovereignty. 100% self-hostable, with no dependency on the US AIOps giants. End-to-end on-premise remains possible.
- One mental model. From collection to an AI-queried graph, it’s the same data, the same vocabulary. Less surface, less glue, less debt.
From tool to engagement
Why does a consultancy build open-source tools rather than just integrate other people’s? Because the rigour we put into these repositories is exactly the rigour we bring to you. Our consultants have all worked in IT production: SenHub Agent and Toise are the building blocks we wished we had had at 3 a.m. What we learn building them — about collection, topology, AI applied to ops — feeds straight back into our monitoring, observability and Monitoring as a Service engagements.
Want to dig in? It’s all on our open-source Labs. And if you’d like to run this at scale without carrying the load, let’s talk about your project.


